
11.30 MB
详情

XPath2Doc(通用网站数据采集及Doc生成工具) V1.0.0.0 中文绿色版
软件类型:网络软件
软件大小:18.1 MB
更新时间:2023-09-07
软件评级:
运行环境:WinAll
软件语言:简体中文
安全监测:
 无插件
无插件
 360 √
360 √
 腾讯 √
腾讯 √
 金山 √
金山 √
 瑞星 √
瑞星 √
无插件
软件介绍
下载地址
XPath2Doc是一个半自动采集网页生成Word docx文件的工具,带企查查、天眼查采集配置,使用XPath2Doc需要自己在WebBrowser窗口里面手工登录,并找到需要的数据页面,然后点击程序按钮进行采集,所以是个半自动的网页数据填充Docx工具。
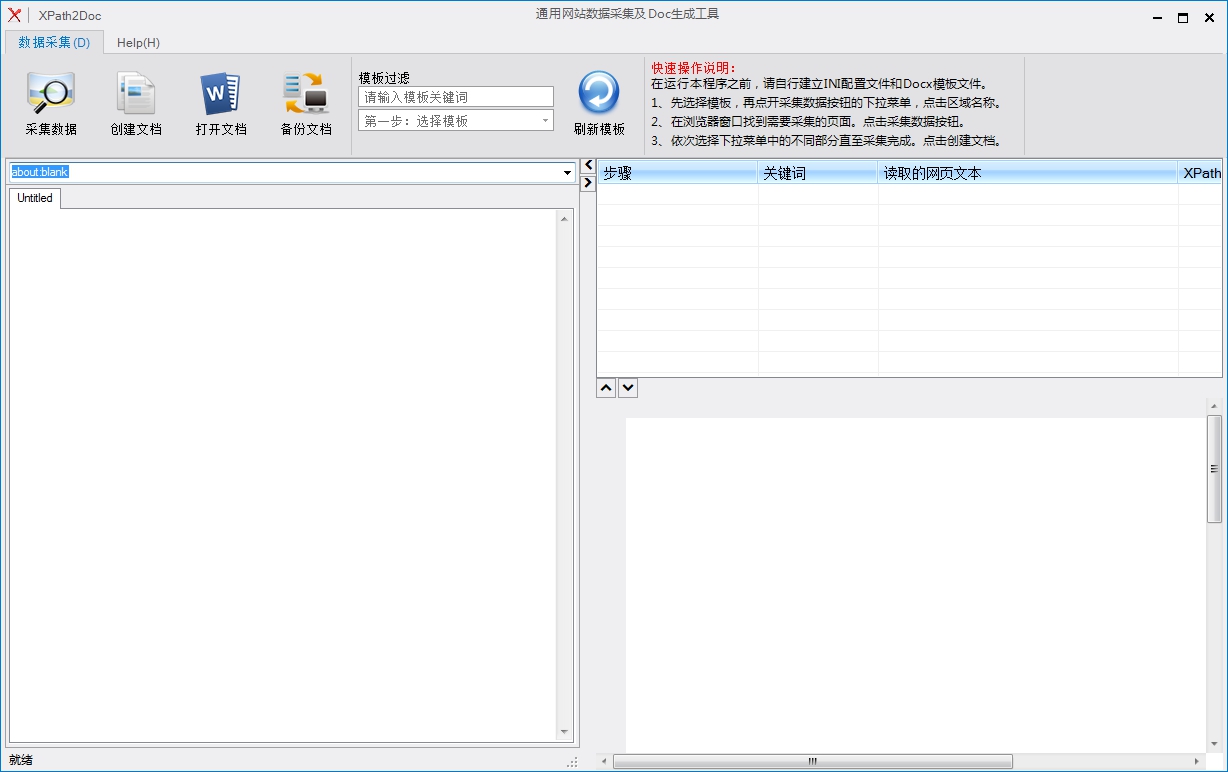
工作原理
网页的每个元素,都可以表示成为XPath语句,所以我们可以读取浏览器打开的网站页面源代码,通过XPath语句得到网页元素中的文本。
XPath语句的获取办法:
通常我们可以使用谷歌的Chrome浏览器打开网站页面,按F12调出开发者工具界面,在ELements选项卡下,随着鼠标的移动可以看到网页内容被阴影覆盖,点开三角符号,可以更进一步定位准确的位置,直到找到最终需要的数据位置。在找到的文本上点鼠标右键,在弹出的菜单中,选择Copy-Copy XPath,然后粘贴到记事本即可得到需要的XPath语句。
这里需要说明一点:如果拷贝出来的XPath语句中有/tbody会影响采集,程序内部对此问题进行了处理,但可能会在某些特殊情况下还是会影响数据采集,可以手工去掉。
运行环境
Windows7 Sp1操作系统请安装下面的组件(重要:VC库如果不安装,本程序无法启动):
VC2017往上
.net framework 4.5.2
在Windows10系统下上述组件一般自带,不需要单独安装。Windows10 1903运行通过。
不支持Windows XP操作系统。
操作说明
1、本程序工作需要三个配置文件:General.ini,自定义.ini,自定义模板.docx。后两个文件名自己定义。
General.ini文件中定义了INI文件和Docx模板文件的存放目录,可以不填,默认是程序所在目录。
自定义.ini、自定义模板.docx是软件使用者自己创建的网页采集XPath语句及最后生成文件所用的Docx模板,具体设置方法请看ini文件中的说明。注意,Docx模板文件中的“@《#0001#》@”之类的字符是在INI文件中定义的用于替换网页采集内容的标记字符串。ini文件中定义了替换关键字的前后缀和模板文件名。
2、使用本程序前,请先建立好你自己的INI配置文件和Docx模板文件。(具体可以参见附带的企查查、天眼查两个配置文件和起诉书模板)
需要说明的是,模板文件支持对文档的不同部分使用不同的网址进行采集,注意Url的设置。
使用方法
启动程序--选择模板--点击采集数据按钮旁边的黑色三角符号,点开下拉菜单,点击需要采集的部分。等候浏览器加载网页完毕,手工输入需要查询的内容,点击查询,找到数据的具体页面,然后点击采集数据按钮,观察右侧的列表中是不是已经得到需要的数据。继续点开下拉菜单,选择下一个需要采集的部分,如果网址发生了变化要等候浏览器加载完毕,找到需要的数据页面。点击采集数据按钮观察右侧列表中是不是得到了第二部分的数据。如此反复,直到数据全部采集完毕。
如果前后两部分的网址相同,在点击下一部分的下拉菜单之前,要先在浏览器中重新查询新的数据,等新数据页面出来之后在点击下拉菜单选择下一部分进行采集。(网址相同的情况下,点击下一部分会直接从网页取数据,如果浏览器没有换页面,数据就错了。)如果某个部分需要重新采集,请先点击下拉菜单中的该部分名称,然后点击采集按钮重复采集该部分(此时可以随意改变浏览器的数据页面,得到的就是不同公司数据)。
列表中采集得到的数据结果如果有偏差,可以单击自行修改。XPath语句如果有什么错误,也可以自己修改看测试结果(XPath语句在修改后会立即重新抓取浏览器的数据,所以浏览器最好是有效数据页面),在程序中修改的XPath语句,不会保存到INI文件中,请自行手工保存。
如果列表中数据无误,预览窗口中的Docx模板内容也正确,则可以点击创建文档按钮,填写要生成的文件名,本软件会使用抓取到的网页数据替换模板中的索引字符串,自动生成Docx文档。
需要说明的是,右下角的Docx预览窗口不能完整的支持Word文档,对不标准的文档可能会出现文本缺失或者错位现象。遇到这种情况,可以忽略,或者将模板文件改成规范的文本格式(单倍行距)。
下载地址
正在读取下载地址...
热门软件
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10

WPS VBA7.1安装包 32&64位 官方免费版
大白菜u盘启动制作工具 V6.0 最新版
912.01 MB
详情
War3永显魔法条 V3.5 绿色版
48 KB
详情
抖音直播伴侣 V0.1.0 官方安装版
113.68 MB
详情
Projection 3D插件 V2.02 绿色版
548.38 KB
详情
2016双12抢购神器 V2.8
15.66 MB
详情
U帮忙 V8.1 双启动版
20.71 MB
详情
黑鲨一键装机大师 V12 官方版
31.24 MB
详情
歪歪卫士 V2.3 绿色版
1.11 MB
详情
Amped DVRConv(监控视频格式转换软件) V15182 英文安装版
192.52 MB
详情
装机必备 更多+
大家都在看
电脑软件专题 更多+